The platform must be versatile sufficient to accommodate evolving project requirements with out changing into a bottleneck. For those excited about assembling a toolkit of open-source MLOps utilities, our article on prime MLOps open-source instruments offers a curated listing for building, training, deploying, and monitoring ML fashions. Amid the passion, firms face challenges akin to these introduced by previous cutting-edge, fast-evolving technologies. These challenges embrace machine learning in it operations adapting legacy infrastructure to accommodate ML techniques, mitigating bias and other damaging outcomes, and optimizing using machine studying to generate earnings whereas minimizing prices. Ethical issues, data privateness and regulatory compliance are additionally critical issues that organizations must address as they combine superior AI and ML technologies into their operations.
Training And Optimizing Ml Fashions
Pipelines must be executed over scalable providers or functions, which might span elastically over a number of servers or containers. This means, jobs complete sooner, and computation resources are freed up as soon as they do, saving important costs. Such tools and technologies are the important thing components of the MLOps toolkit, which help roll out, undertake, and follow MLOps in any project.
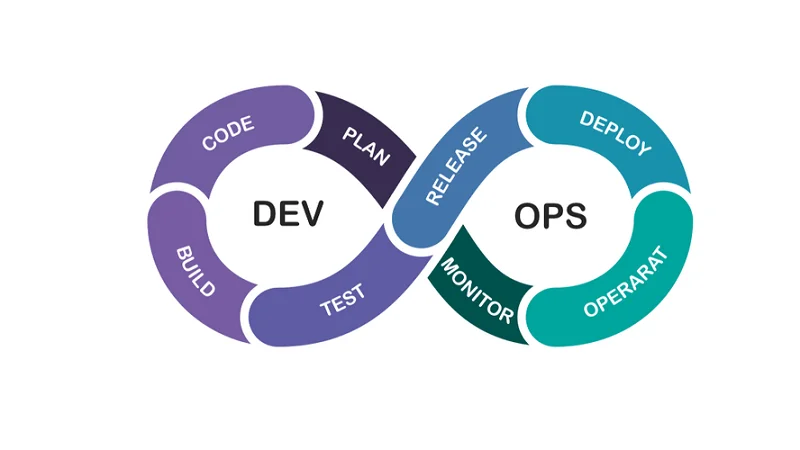
Development 5: Democratization Of Mlops
Furthermore, batch assortment and preparation methodologies such as ETL, SQL queries, and batch analytics don’t work properly for operational or real-time pipelines. As a end result, ML groups typically build separate data pipelines which use stream processing, NoSQL, and containerized micro-services. 80% of knowledge at present is unstructured, so a vital part of constructing operational data pipelines is to convert unstructured textual, audio and visual information into machine learning- or deep learning-friendly data organization. Organizations are inclined to put an excessive quantity of emphasis on the creation of ML models and inserting them behind some API end level. The knowledge science and model development course of must be a fundamental a half of constructing any modern application.
Machine Studying Mannequin Management: What It’s, Why You Should Care, And Tips On How To Implement It
As the model evolves and is exposed to newer information it was not educated on, an issue referred to as “data drift” arises. Data drift will occur naturally over time, because the statistical properties used to coach an ML model become outdated, and can negatively influence a business if not addressed and corrected. With that, new points maintain popping up, and ML builders together with tech companies keep constructing new tools to care for these issues. Synchronize DevOps and ModelOps to build and scale AI models across nearly any cloud. Machine learning and MLOps are intertwined concepts however symbolize completely different levels and objectives inside the overall process. The overarching goal is to develop correct models able to undertaking numerous tasks such as classification, prediction or offering suggestions, making certain that the top product effectively serves its supposed purpose.

It’s the spine that ensures the well being and longevity of machine learning operations. Monitoring within the “MLOps which means” context includes keenly observing the performance metrics of ML models when they’re within the wild, deployed, and in motion. A important concern is mannequin drift, a phenomenon where the model’s performance wanes due to evolving data. To really perceive “what’s machine studying operations,” one wants to grasp how crucial it’s to detect such drifts.

In distinction, for level 1, you deploy a coaching pipeline that runs recurrently to serve the trained mannequin to your other apps. Manual ML workflows and a data-scientist-driven course of characterize stage zero for organizations simply starting with machine learning techniques. Reproducibility in an ML workflow is necessary at each section, from data processing to ML mannequin deployment.
ML pipelines type the core of MLOps, streamlining the journey from data collection to mannequin deployment. Next, in characteristic engineering, significant attributes are derived or highlighted for fashions to discern patterns. The core action happens in mannequin training, the place algorithms study from the refined data.
For a easy machine learning workflow, each knowledge science team should have an operations team that understands the unique necessities of deploying machine studying models. Outside of Uber and far outdoors of Silicon Valley, we’ve seen a rising number of early adopters deliver DevOps rules and automation not just to their software engineering, but also to their knowledge science teams by way of MLOps. Of course, ML continues to be far more painful than software program for many companies, for causes that I outlined in this blog. But I’m satisfied that the trade is steadily heading in the path of a future in which your typical information scientist in your typical Fortune 500 organization is prepared to iterate on an operational ML mannequin multiple instances a day. DVC addresses these points by managing large files by way of metadata and exterior storage (such as S3, Google Cloud Storage, or Azure Blob Storage) whereas sustaining detailed tracking of data changes and model historical past. DVC makes use of human-readable metafiles to define information versions and integrates with Git or any supply management administration (SCM) tool to model and share the complete project, including knowledge assets.
A TFX Component calledTensorFlow Model Analysis (TFMA)allows you to simply consider new models against current ones earlier than deployment. Consider Adstocrat, an promoting company that gives online corporations with environment friendly ad tracking and monitoring. They have worked with huge firms and have recently gotten a contract to construct a machine studying system to foretell if clients will click on an ad shown on a webpage or not.
For deeper insights into mannequin and data efficiency, Databricks mechanically shops inference request data in Delta Tables. This feature enables detailed analysis and facilitates the identification of tendencies or anomalies over time. Users can arrange notebook jobs to question this inference knowledge, performing statistical analysis to detect mannequin drift or data high quality issues. This setup leverages baselines established from MLflow training knowledge, providing a complete view of mannequin habits in manufacturing environments. This analysis focuses totally on the manufacturing features of Machine Learning, distinguishing between important (“table stakes”) and superior (“best-in-breed”) options inside MLOps platforms. For insights into the mannequin experimentation facet, notably between Vertex AI and SageMaker, we suggest exploring external resources that present detailed comparisons.
Imagine a situation the place a financial institution deploys a credit threat assessment model without proper management. The model’s efficiency degrades over time, leading to inaccurate threat assessments, elevated defaults, and, in the end, monetary losses. Such challenges underscore the critical importance of robust ML model administration. This level allows individuals and organizations to keep a full history of experiments by storing and versioning their notebooks/code, knowledge and model, in addition to just logging metadata.
- Evaluation is important to make sure the fashions carry out nicely in real-world eventualities.
- While the operator knows the proper answers to the issue, the algorithm identifies patterns in knowledge, learns from observations and makes predictions.
- ML also enhances search engine outcomes, personalizes content and improves automation efficiency in areas like spam and fraud detection.
- The aim of MLOps level 1 is to perform continuous training (CT) of the model by automating the ML pipeline.
- Essentially, SageMaker Model Build Pipelines may be likened to a Continuous Integration (CI) system for machine studying.
While the operator is aware of the proper answers to the problem, the algorithm identifies patterns in information, learns from observations and makes predictions. The algorithm makes predictions and is corrected by the operator – and this process continues till the algorithm achieves a excessive degree of accuracy/performance. When you combine model workflows with steady integration and continuous supply (CI/CD) pipelines, you limit efficiency degradation and keep high quality for your model. For instance, software program engineers can monitor mannequin performance and reproduce behavior for troubleshooting.
Additionally, DVC integrates with existing ML frameworks like TensorFlow and PyTorch. You can do it by utilizing a couple of native or cloud providers just like the AWS S3 Bucket, RDBMS (Postgresql, Mongo…), and writing a simple python API to make it easy to update the database data in case changes or updates. Tools like Neptune and MLflow allow you to install their software domestically, so you can add this functionality to your deployment server. All of these challenges make it inconceivable to breed the outcomes of any specific experiment. In order to handle the challenges of this degree, a great begin is to add versioning to our models and data – some experiment instruments do that out-of-the-box. As mentioned earlier, ML/DL is experimental in nature, and we use experiment monitoring tools for benchmarking different fashions.
This stage is essential for gathering the data that will be the foundation for further analysis and mannequin coaching. The MLOps pipeline comprises various components that streamline the machine studying lifecycle, from growth to deployment and monitoring. Continuous monitoring of mannequin efficiency for accuracy drift, bias and different potential points performs a critical function in maintaining the effectiveness of models and stopping surprising outcomes.
Although algorithms sometimes perform better after they practice on labeled information units, labeling could be time-consuming and expensive. Semisupervised learning combines parts of supervised learning and unsupervised studying, hanging a stability between the previous’s superior efficiency and the latter’s efficiency. For example, e-commerce, social media and information organizations use suggestion engines to counsel content based mostly on a customer’s past habits. In self-driving cars, ML algorithms and laptop imaginative and prescient play a important role in protected highway navigation. Other frequent ML use instances include fraud detection, spam filtering, malware risk detection, predictive upkeep and business course of automation.
Transform Your Business With AI Software Development Solutions https://www.globalcloudteam.com/ — be successful, be the first!